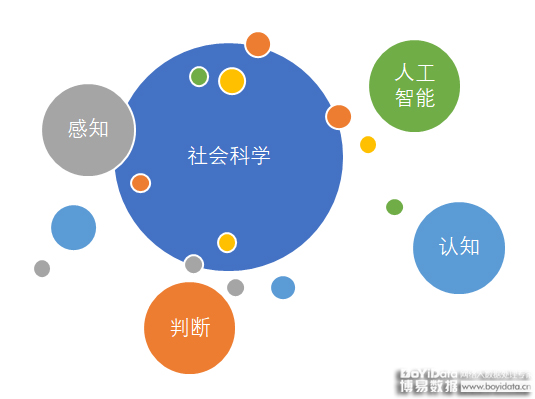

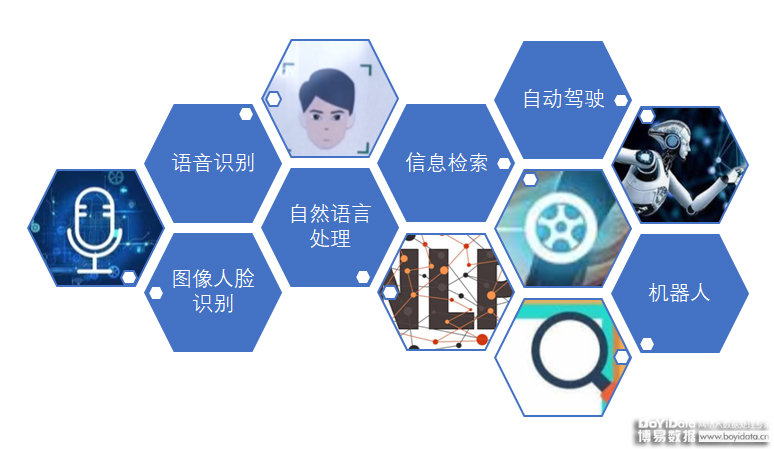

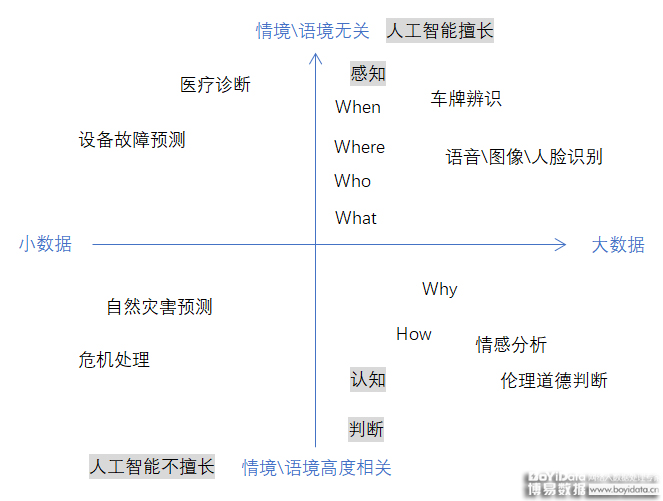
——对语境和场景的认知

[1] Marr, B. (2016). What is the difference between artificial intelligence and machine learning? Forbes. Retrieved from:
https://www.forbes.com/sites/bernardmarr/2016/12/06/what-is-the-difference-between-artificial-intelligence-and-machine-learning/#66fdb6862742.
[2] Knowledge@Wharton (2018). Vishal Sikka: Why AI needs a broader, more realistic approach. Retrieved fromhttp://knowledge.wharton.upenn.edu/article/ai-needsbroader- realistic-approach/.
[3] Daugherty, P., Carrel-Billiard, M., & Biltz, M. (2018). Accenture technology vision 2018. Retrieved from. Intelligent Enterprise Unleashed. Accenturehttps://www. accenture.com/t00010101T000000Z__w__/nz-en/_acnmedia/Accenture/next-gen-7/tech-vision-2018/pdf/Accenture-TechVision-2018-Tech-Trends-Report.pdf#zoom=50.
[4] Valin, J. (2018). Humans still needed: An analysis of skills and tools in public relations. Discussion paper. Retrieved from London: Chartered Institute of Public Relations. https://www.cipr.co.uk/sites/default/files/11497_CIPR_AIinPR_A4_v7.pdf.
[5] Searle, J. (1980). Minds, brains and programs. Behavioral and Brain Sciences, 3, 417-457. doi10.1017/S0140525X00005756.
[6] Silver, D.,Huang, A., & Maddison, C. J. ect. (2016). Mastering the game of Go with deep neural networks and tree search. Nature: 484–489. doi:10.1038/nature16961.
[7] 2018AI界的第一件大事记:索菲亚原来是个“骗子”. 新浪财经头条. 2018年8月22日. https://t.cj.sina.com.cn/articles/view/5612652531/14e8a47f300100cm5j
[8] Adam J. Gustein & John Sviokla. 7 Skills That Aren’t About to Be Automated. Harvard Business Review. 2018年7月17日。https://hbr.org/2018/07/7-skills-that-arent-about-to-be-automated?utm_medium=social&utm_campaign=hbr&utm_source=facebook&from=timeline
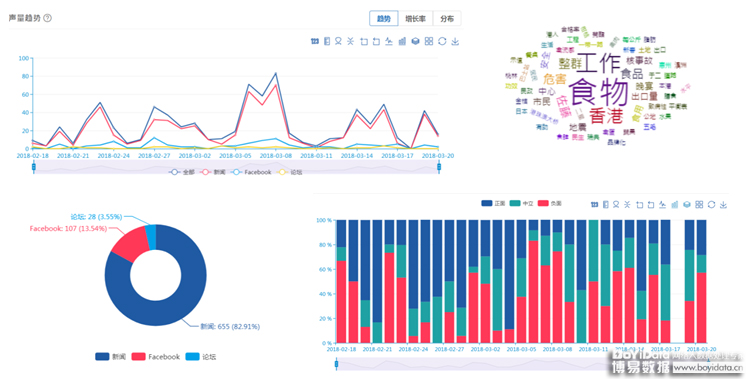
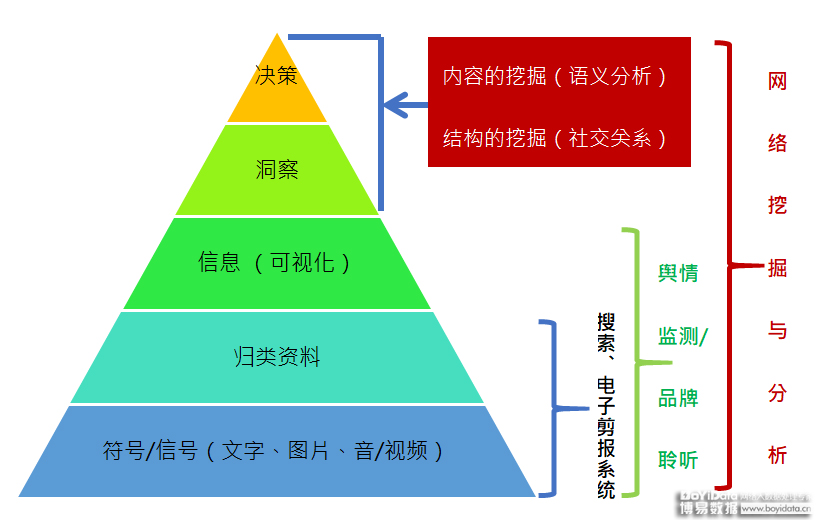
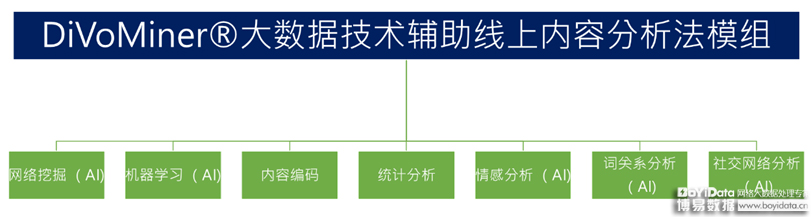
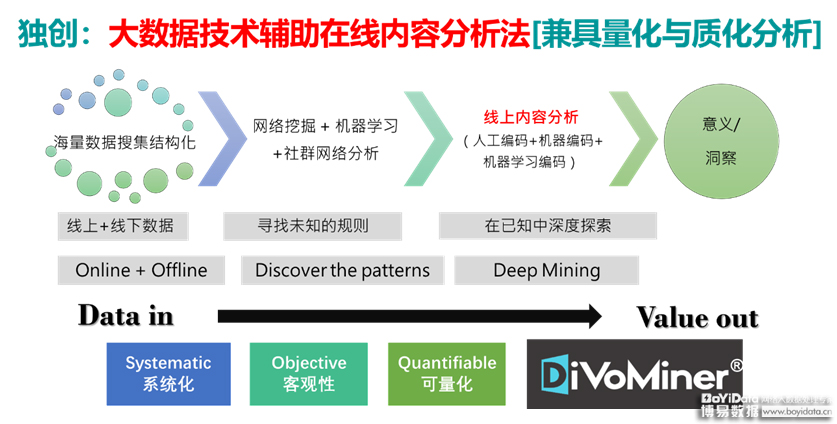
[9] Parnas, & Lorge, D. . (2017). The real risks of artificial intelligence. Communications of the ACM, 60(10), 27-31.
[10] 张荣显,曹文鸳:《网络舆情研究新路径:大数据技术辅助网络内容挖掘与分析》,《汕头大学学报》(人文社会科学版)2016年,第8期,第111-121页。